Preparación examen (Test)
Pregunta 1
Dada la siguiente imagen, son atributos los elementos
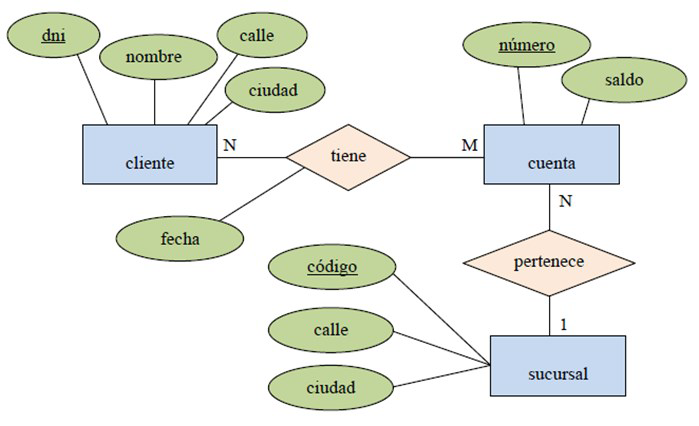
dni, nombre, calle, ciudad.
cliente, cuenta y sucursal.
tiene, pertenece.
Pregunta 2
La ventaja de usar XML Schema frente a DTD es:
Usa sintaxis XML y permite especificar un número de repeticiones para los elementos.
Permiten especificar tipos de datos.
Las dos anteriores son correctas.
Pregunta 3
Almacenar datos XML en DBMS relacionales:
Es una opción habitual porque mantiene compatibilidad con aplicaciones existentes.
No es la mejor opción porque la transformación de un XML a datos relacionales es muy costosa.
Siendo una opción válida, no es muy utilizada porque hay que modificar todas las aplicaciones.
Pregunta 4
En un sistema de BD paralelo, la ampliabilidad hace referencia a:
Reducción del tiempo de ejecución.
Tiempo para terminar una tarea.
Longitud de las transacciones que se pueden manejar.
Pregunta 5
La fragmentación de una tabla en un sistema de BD distribuido debe ser disjunta:
Siempre.
Siempre, con una excepción muy concreta en la fragmentación vertical.
Siempre, con una excepción muy concreta en la fragmentación horizontal.
Pregunta 6
En asociación estática, supóngase un problema de asociación por clave de búsqueda "saldo" (de una cuenta bancaria), cuya función de asociación que distribuye las claves en cajones con los siguientes rangos: 1 - 10.000, 10.001 - 20.000, 20.001 - 30.000, ... hasta un valor máximo de 100.000. Esta función:
Es una buena opción, porque es aleatoria y uniforme.
No es una buena opción porque no es uniforme.
No es una buena opción porque no es aleatoria.
Pregunta 7
El intercambio de información entre el área privada de una transacción y memoria principal:
Puede suponer la transferencia de información desde el disco a memoria.
Puede suponer la transferencia de información desde la memoria al disco.
Las dos anteriores son correctas.
Pregunta 8
La optimización de consultas hace referencia a:
La construcción de expresiones algebraicas equivalentes a la dada por el usuario, pero más eficiente.
La estrategia de ejecución de la consulta.
Las dos anteriores son correctas.
Pregunta 9
La responsabilidad de asegurar el aislamiento de una transacción es del:
Gestor de transacciones.
Gestor de recuperaciones.
Controlador de concurrencia.
Pregunta 10
Cuando calculan el precio del seguro de nuestro coche, nos encontramos ante un caso de aplicación de minería de datos de tipo:
Predicción.
Asociación.
Agrupación.
Pregunta 11
En un sistema OLAP, una operación de concreción:
Cambia la dimensión de estudio.
Disminuye el nivel de granularidad.
Aumenta el nivel de granularidad.
Pregunta 12
Las BD y los sistemas de recuperación de información:
Se diferencian en que en las BD el procesamiento transaccional es de suma importancia mientras que en los sistemas de recuperación son menos importantes.
Se parecen en que el procesamiento de transacciones es una parte muy importante de su funcionamiento.
Se diferencian en que las transacciones en la BD deben ser atómicas y en los sistema de recuperación no.
Pregunta 13
En sistemas de recuperación de información, considerar el número de apariciones de un término en un documento como medida de su relevancia:
Es buena idea porque se asume que cuantas más veces aparezca, mayor relevancia tendrá el documento en relación a dicho término.
No es buena idea porque el número de apariciones del término está relacionado con la longitud del documento
No es buena idea porque el HTML puede tener metainformación con dicho término que haga que el conteo de apariciones no sea correcto.
Pregunta 14
La contaminación de motores de búsqueda:
Hace referencia a la desactualización de los algoritmos de búsqueda.
Es más sencilla en el algoritmo HITS.
Es más sencilla en el algoritmo PageRank.
Pregunta 15
La principal ventaja de la búsqueda lineal es que:
Es más rápida.
Que se puede usar en todos los casos.
Recorre toda la relación.
Pregunta 16
¿Cuál es la medida de referencia que se utiliza en los sistemas de gestión de bases de datos para evaluar el coste de una consulta?
El tiempo de CPU en ejecutar una consulta.
El costo de la comunicación.
El coste de acceso a los datos en disco.
Ninguna de las anteriores.
Pregunta 17
La minería de datos se aplica en problemas de:
Predicción, asociación y agrupación.
Predicción, agrupación y asociación.
Asociación, agrupación y clasificación.
Ninguna de las anteriores.
Pregunta 18
Marca la respuesta correcta:
Todos los documentos XML deben tener una etiqueta raiz.
Todas las etiquetas son sensibles a mayúsculas/minúsculas.
Todas las etiquetas tienen que estar correctamente anidadas.
Todas las anteriores son correctas.
Pregunta 19
Ante un fallo del SGBD:
No se puede recuperar la información del almacenamiento volátil.
El almacenamiento no volátil debe ser restaurado.
Sería ideal disponer de un almacenamiento estable.
Todas las anteriores son correctas.
Pregunta 20
¿Cuál de los siguientes es un esquema de Data Warehouse?
ROLAP estrella.
MOLAP.
Relacional.
Copo de nieve.
Pregunta 21
Los pasos que realiza el gestor de bases de datos para obtener una consulta válida son:
Analizar y traducir, Optimizar, Evaluar.
Leer consulta, Ejecutar, Devolver datos.
Analizar, Crear álgebra relacional, Ejecutar.
Ninguna de las anteriores.
Pregunta 22
Ante una caída del sistema:
Nos encontramos ante un fallo que afecta al almacenamiento permanente.
Puede ser debido a un fallo interno o externo al sistema.
No existe este tipo de errores.
Ninguna de las anteriores.
Pregunta 23
Marca la respuesta correcta:
Siempre que un documento XML no tenga errores de sintaxis se puede decir que es válido.
En un documento XML, un elemento puede no contener ningún valor.
En un documento XML, todo elemento debe contener al menos un elemento hijo.
Ninguna de las anteriores.
Pregunta 24
Una aproximación ante un fallo es:
Volver a ejecutar la transacción en todos los casos.
Deshacer los efectos de la transacción en todos los casos.
Esperar a que ocurra el fallo y después realizar alguna acción.
Ninguna de las anteriores.
Pregunta 25
Un ejemplo de base de datos clave-valor es:
DynamoDB.
MySQL.
Oracle SQL.
OrientDB.
Pregunta 26
De las siguientes opciones, indique cuál de ellas es una base de datos no relacional:
Mongo DB.
Dynamo DB.
Elasticsearch.
Todas las opciones son correctas.
Pregunta 27
Indica cuál o cuáles de las siguientes bases de datos son orientadas a grafos.
Neo4j.
MongoDB.
OrientDB.
A y C son correctas.
Todas son correctas.
Pregunta 28
Indique cuál de las siguientes implementaciones de OLAP almacena datos en una base de datos relacional con tablas de-normalizadas:
DOLAP
MOLAP
ROLAP
XOLAP
Pregunta 29
La minería de datos intenta buscar conocimiento a partir de los datos almacenados en grandes bases de datos o data warehouses.
Verdadero.
Falso.
Pregunta 30
Dado el siguiente XML Schema:
xxxxxxxxxx201 2<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">3 <xs:element name="pizzas"/>4 <xs:element name="pizza">5 <xs:complexType>6 <xs:sequence>7 <xs:element name="ingredientes">8 <xs:complexType>9 <xs:sequence>10 <xs:element name="nombre" type="xs:string" minOccurs="1" maxOccurs="5"/>11 </xs:sequence>12 </xs:complexType>13 </xs:element>14 </xs:sequence>15 <xs:attribute name="nombre" type="xs:string" use="required"/>16 <xs:attribute name="precio" type="xs:positiveInteger" use="required"/>17 <xs:attribute name="vegan" type="xs:boolean" use="required"/>18 </xs:complexType>19 </xs:element>20</xs:schema>
Y el siguiente XML:
xxxxxxxxxx301 2<pizzas xmlns:xsi=http://www.w3.org/2001/XMLSchema-instance xsi:noNamespaceSchemaLocation="PizzaSchema.xsd">3 <pizza nombre="carnivora" precio="25" vegan="false">4 <ingredientes>5 <nombre>peperoni</nombre>6 </ingredientes>7 </pizza>8 <pizza nombre="bbq" precio="18" vegan="false">9 <ingredientes>10 <nombre>beacon</nombre>11 <nombre>pollo</nombre>12 </ingredientes>13 </pizza>14 <pizza nombre="hawaiana" precio="12" vegan="false">15 <ingredientes>16 <nombre>piña</nombre>17 <nombre>jamon york</nombre>18 <nombre>queso</nombre>19 </ingredientes>20 </pizza>21 <pizza nombre="especial" precio="30" vegan="false">22 <ingredientes>23 <nombre>aceituna</nombre>24 <nombre>beacon</nombre>25 <nombre>queso</nombre>26 <nombre>tomate</nombre>27 <nombre>salsa especial</nombre>28 </ingredientes>29 </pizza>30</pizzas>
¿Podríamos decir que el XML es válido frente al XML Schema?
Verdadero.
Falso.
Pregunta 31
Indique qué operación u operaciones pueden beneficiarse de la ejecución paralela en Oracle:
CREATE INDEX.
GROUP BY.
UPDATE.
SELECT
B, C Y D son correctas.
Todas son correctas.
Pregunta 32
Una compañía ha decidido hacer uso de una base de datos distribuida para servir datos a una aplicación web. Para el almacenamiento de los datos han optado por un modelo de replicación con 10 réplicas repartidas a lo largo de varios continentes. Indique la opción correcta:
Las operaciones de lectura sobre las réplicas tendrán un tiempo de respuesta muy elevado debido a esta decisión.
Cada nodo del sistema tendrá una parte de la totalidad de los datos de la empresa.
Las operaciones de escritura introducen complejidad en el sistema debido a esta decisión.
Ninguna opción es correcta.
Pregunta 33
Un índice ordenado se denomina secundario si se realiza sobre cualquier campo (a excepción de la clave primaria) de la tabla, siempre que NO contenga duplicados.
Verdadero.
Falso.
Pregunta 34
Cuando una transacción está en estado "Fallida" podemos asegurar que ya se han revertido todas las acciones realizadas previamente en la transacción y que la base de datos se encuentra en el estado previo a la ejecución de la misma.
Verdadero.
Falso.
Pregunta 35
Un ejemplo de base de datos clave-valor es:
DynamoDB.
MySQL.
Oracle SQL.
OrientDB.
Pregunta 36
Un ejemplo de base de datos clave-valor es:
Apache Cassandra.
MySQL.
Oracle SQL.
OrientDB.
Pregunta 37
En una base de datos no relacional orientada a grafos los nodos representan las relaciones y las aristas las entidades.
Verdadero.
Falso.
Pregunta 38
Indique cuál de las siguientes implementaciones de OLAP almacena datos en una base de datos multidimensional:
XYZOLAP
MOLAP
ROLAP
XOLAP
Pregunta 39
Los sistemas de visualización generados a partir de la minería de datos sirven para que los usuarios tomen decisiones en base a los datos recogidos.
Verdadero.
Falso.
Pregunta 40
Un documento XML sintácticamente correcto y validado contra un esquema XML o DTD se dice que es "correcto" y "bien formado".
Verdadero.
Falso.
Pregunta 41
Sobre el paralelismo en operaciones, indique la opción correcta:
Consiste en ejecutar en paralelo cada una de las operaciones de forma separada.
Consiste en ejecutar en paralelo los diferentes pasos de una única operación.
Es especialmente útil para selecciones y ordenaciones.
B y C son correctas.
Pregunta 42
Una compañía ha decidido hacer uso de una base de datos distribuida para servir datos a una aplicación web. Para el almacenamiento de los datos han optado por un modelo de replicación con 10 réplicas repartidas a lo largo de varios continentes. Indique la opción correcta:
La aplicación sufrirá latencias extremadamente altas debido a esta decisión.
Cada nodo del sistema tendrá una parte de la totalidad de los datos de la empresa.
Las operaciones de escritura serán extremadamente rápidas y no introducen complejidad en el sistema debido a esta decisión.
Ninguna opción es correcta.
Pregunta 43
Un índice ordenado se denomina secundario si se realiza sobre la clave de ordenación en disco de la tabla.
Verdadero.
Falso.
Pregunta 44
Una transacción que termina de forma correcta es una transacción:
Abortada.
Comprometida.
Compensadora.
Correcta.
Pregunta 45
De las siguientes opciones, indique cuál de ellas es una base de datos relacional:
Mongo DB.
Dynamo DB.
My SQL.
Todas las opciones son correctas.
Pregunta 46
Los pasos de un proceso ETL son:
Extracción, tonificación y carga.
Extracción, transformación y carga.
Descarga, transformación y carga.
Ninguna opción es correcta.
Pregunta 47
Los sistemas de visualización generados a partir de la minería de datos toman decisiones por los usuarios en base a los datos recogidos.
Verdadero.
Falso.
Pregunta 48
Acerca de XML Schema, indique la opción correcta:
Están escritos en XML.
Admiten tipos de datos.
Admiten espacios de nombres.
Todas las opciones son correctas.
Pregunta 49
Sobre el paralelismo entre consultas, indique la opción correcta:
Consiste en ejecutar en paralelo cada una de las operaciones de forma separada.
Consiste en ejecutar en paralelo los diferentes pasos de una única operación.
Disminuirá en cualquier caso el tiempo empleado (tiempo de respuesta) en procesar cada operación.
A y C son correctas.
Pregunta 50
Indique cuál o cuáles de los siguientes aspectos son ventajas de una base de datos distribuidas:
Autonomía.
Disponibilidad.
Datos compartidos.
Todas las opciones son correctas.
Pregunta 51
Un índice ordenado se denomina primario si se realiza sobre la clave de ordenación en disco de la tabla.
Verdadero.
Falso.
Pregunta 52
Una transacción que no termina de forma correcta es una transacción:
Abortada.
Comprometida.
Compensadora.
Fallida.
Pregunta 53
En el Modelo Entidad Relación, los atributos se representan como:
Rectángulos.
Óvalos.
Rombos.
Pregunta 54
La ventaja de usar XML Schema frente a DTD es:
Usa sintaxis XML y permite especificar un número de repeticiones para los elementos.
Permiten especificar tipos de datos.
Las dos anteriores son correctas.
Pregunta 55
Almacenar datos XML en DBMS relacionales:
Es una opción habitual porque mantiene compatibilidad con aplicaciones existentes.
No es la mejor opción porque la transformación de un XML a datos relacionales es muy costosa.
Siendo una opción válida, no es muy utilizada porque hay que modificar todas las aplicaciones.
Pregunta 56
En un sistema de BD paralelo la granularidad fina es:
Muchos procesadores menos potentes.
Pocos procesadores muy potentes.
Muchos procesadores con menos memoria.
Pregunta 57
En un sistema de BD distribuidas, la fragmentación horizontal:
Se realiza con una operación de selección y se reconstruye con la unión.
Se realiza con una operación de proyección y se reconstruye con la unión.
Se realiza con una operación de selección y se reconstruyen con un join.
Pregunta 58
Un índice denso es el que tiene una entrada:
Por cada bloque de disco.
Por cada valor de clave primaria.
Por cada valor de búsqueda.
Pregunta 59
Un fallo en una transacción puede ser:
De tipo lógico, si se trata de un problema interno de la propia transacción.
De tipo lógico, si se trata de un problema externo de la propia transacción.
De tipo lógico, si ha ocurrido un interbloqueo.
Pregunta 60
La optimización de consultas hace referencia a:
La construcción de expresiones algebraicas equivalentes a la dada por el usuario, pero más eficiente.
La estrategia de ejecución de la consulta.
Las dos anteriores son correctas.
Pregunta 61
Una transacción compensadora:
Es aquella que deshace los efectos de una transacción comprometida y que el sistema ejecuta cuando necesita abortarla.
Es aquella que deshace los efectos de una transacción parcialmente comprometida, que el sistema ejecuta cuando necesita abortarla.
Es aquella que deshace los efectos de una transacción comprometida, que debe ejecutar el usuario.
Pregunta 62
En un árbol de decisión, la medida de Gini:
Es 0 cuando todos los elementos son de la misma clase.
Es mayor cuanto más número de conjuntos hay.
Alcanza el máximo cuando todos los elementos son de la misma clase.
Pregunta 63
En un sistema OLAP, una operación de abstracción:
Cambia la dimensión de estudio.
Disminuye el nivel de granularidad.
Aumenta el nivel de granularidad
Pregunta 64
En sistemas de recuperación de la información, un falso positivo es:
Recuperar documentos sin relevancia.
Depende del algoritmo de relevancia que estemos usando.
No recuperar elementos relevantes.
Pregunta 65
En un sistema de recuperación de información cuando el usuario no indica ninguna conectiva lógica:
Se asume que las palabras clave están indicadas por orden de importancia.
Se asume que las palabras clave se conectan por "o".
Se asume que las palabras clave se conectan por "y".
Pregunta 66
En sistemas de recuperación de información, las palabras de parada son:
Palabras que no se tienen en cuenta como palabras clave por ser demasiado frecuentes.
El número de palabras máximo que se analiza en el documento, tras el cual se asume que la información sobre palabras clave ya es redundante.
Palabras de máxima importancia, cuya frecuencia es muy baja y que, una vez localizadas, dan máxima relevancia al documento.
Pregunta 67
La propiedad de las transacciones denominada aislamiento se refiere a:
La ejecución aislada de una transacción conserva la consistencia de la BD.
Para cada par de transacciones, se cumple que para los efectos de cada una de ellas, la otra no ha empezado o ya ha finalizado cuando comienza su ejecución.
Los efectos de la transacción que finaliza con éxito permanecen en la BD.